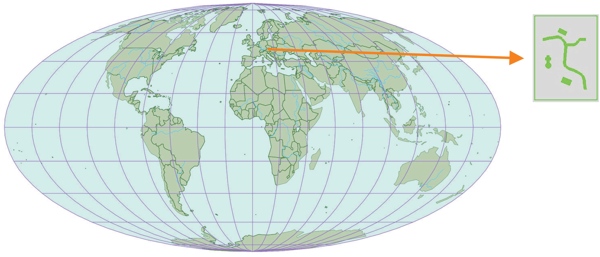
 Figure 1 extracting a map out of seamless data
Figure 1 extracting a map out of seamless data
Today the important map-companies store their digital data seamlessly or in a system of tiles. If a map is printed, the data for the selected range is extracted from the base-data. There is no difference in this procedure between own company maps and customer orders. At this step of extraction, all data on the range borders will be cut. In particular text with large spacing like names for mountain ranges are clipped off. The map user is unable to read and understand the names of relevant locations. If the map-producer does not want to have clipped names, he has to either delete the names, to scale them or to move them. This is the most important working part of the ?border-cleaning? of the map. Due to the high labour costs in Center-Europe, the expenses for border- cleaning are high. This is especially relevant when creating
- an atlas
and
-periodically printed maps.
Figure 1 extracting a map out of seamless data
When producing an atlas, border-cleaning is needed for each page. Maps, which are printed each year, need a yearly border-cleaning. Because of this reason some map companies and goverment map departments stop border cleaning and use overlapping zones on the maps. In the following paper two methods are presented, that show how with the use of intelligent IT-functions and data processing the costs and the work of border-cleaning can be reduced dramatically.
Till now the procedure to make a map or atlas out of seamless data has been the following. Each atlas page or finished map consists of two parts:
1) a (geo-)map with the geographical/geo-located data as content
2) a map-border with the border descriptions, logo, search-fields, etc.
Both sections will be connected for the finalised output as PDF print file.
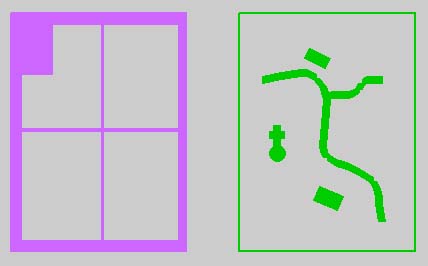 Figure 2 example of the two datasets/drawings for an atlas page
Figure 2 example of the two datasets/drawings for an atlas page
When preparing the output both sections will be managed as seperated datasets. In the various GI-software-programs these datasets have different names, e.g. models. In CAD-programs this means that two designfiles or drawing files will be used. In one of the files or drawings there is the geographical content and in the other file or drawing there are the border-graphics. This mind-model with two files or drawings is specially useful, because it shows special consideration on the management of rights of the graphical elements. In a masterfile or masterdrawing elements can be manipulated, where in a reference- file/drawing, which is located behind the masterdrawing, no data arrangments are possible. With the use of the reference-file/drawing technique the cartographer has the possibility to work in the map-border-file and he is not able to make changes in the (geo-) base-data, the software blocks it.
The referenced (geo-)data is not the original base-data, it is a copy of the data in the range of the output-map. It is a ?copy?, because changes are made on the elements, which overlap the border. This is known as ?border-cleaning?. The following list shows the changes, that are made at the border-cleaning for text- elements:
 Figure 3 text manipulations
Figure 3 text manipulations
1. deletion of non-important names
2. movement of names into the printed map-range (see figure 4)
3. placement of important names, which are necessary for the orientation of the user
4. resizing of names or use of different text-style, so that the names are full seen in the printed range. This change is sneakly and possible in CAD-mapping-programs, but it breaks with the philosophy of gi-systems, which says one layer has one outlook.
In this classic workflow every time an actualized map is made all the changes on the elements have to be made again! Awful! The work is done by hand. Each time errors can happen, correction loops are necessary. This takes time and time is money. Therefore the border-cleaning is today often not done. As an alternative neighbouring pages have thick overlapping ranges.
For all described border-cleaning concepts the following is to be applied:
It doesn´t matter whether the data is stored in a file-oriented system or in one or more big databases. In the paper the expressions ?mapborder-drawing? and ?geo-drawing? are used to define the two groups of data, which are necessary for the output-map. All concepts can only be realized when software-functions for manipulation of elements in the data storage exists, e.g. SQL. The optimal storage in the data base has already been explained in detail (Samet, 1989).
The aim of a modern border cleaning system is to avoid changes on the base-data (or the copy of the base-data). But all the necessary changes for border cleaning will be remembered by the system.
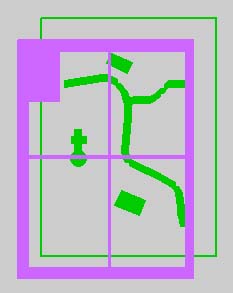 Figure 4 the mapborder-drawing (masterfile) in front of the geo-drawing (reference-file)
Figure 4 the mapborder-drawing (masterfile) in front of the geo-drawing (reference-file)
In this concept the mapborder-drawing carriers the complete border cleaning information. The geo-drawing has to be created out of the base data and before the new version of the map is released. The mapborder-drawing will be kept all the time. In the mapborder-drawing only few changes have to be made like the production-date of the map, because the range of the map/page will not be modified.
Now an overview of the working with the text (or symbols) on the map-range-border will be made. All work is done in the mapborder-drawing.
- Masks are created for the whole text, which lay in the geo-drawing and intersect the border.
- New text is placed or a copy of the text from the geo-drawing is created in the mapborder-drawing and is moved to a different position.
Finally a software mixes the two files together. This software puts all elements of the geo-drawing in the output-map, which do not have a mask in the mapborder-drawing. All data without the masks from the mapborder-drawing will be copied in the output-map.
This concept of border-cleaning makes it possible, that when the next output-map is created again, only the geo-map-file has to be changed. Nevertheless, it is necessary a control of the elements on the map-range. It is possible, that a text in the geo-drawing-data is moved, new or deleted. So the mask must be moved, new created or deleted.
The big advantage of this concept for border-cleaning is, that it reduces about 95 % of the work necessary for the next output of the same map-range.
The important part in this concept is the software, it has to combine the two different data sets. More electronic data processing (EDP) can support the cartographer:

- automatic creation of mask around all text/symbols, which have to be cut from the maprange-borderline.
- a "Goto"-function jumps from element to element at the maprange-borderline.
So the cartographer cannot oversee an element. The function can be imagined like the
control of a videorecorder with to "go forward", "go back", "fast forward", "fast back"
and "go to position at" function.
Before thinking, how the border-cleaning can be done almost automatically, it is necessary to look into the data and its structure. Following element-types are in the data:
• Image
• Line
• Area
• Point(symbol)
• Text
There are 3 classic methods to extract data for a range:
Inside
Overlap
Clip
 Figure 6 methods of data extraction
Figure 6 methods of data extraction
The typical method for extracting a page/map out of seamless data is the clip method. But a closer look into the different element-types shows problems when clipping. Different solutions are necessary.
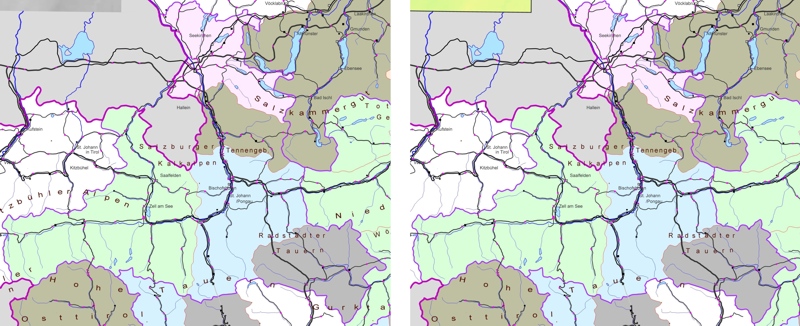
Figure 7
on the left side – standard clipping means unreadable names
on the right side – all elements without the names is clipped, only names, which are fully inside the range, are displayed; this brings too a big loose of information!
The example demonstrated very good, that an intelligent clipping is necessary, specially for text-elements!
Normally shading is stored in gray or colored images. An image is always rectangular. In some raster formats the geolocation-parameters are stored (e.g. geotiff), sometimes in seperate files (e.g. tfw) The cutting of an rectangular image is easy. A lot of applications can do this. Therefore no more considerations are necessary.
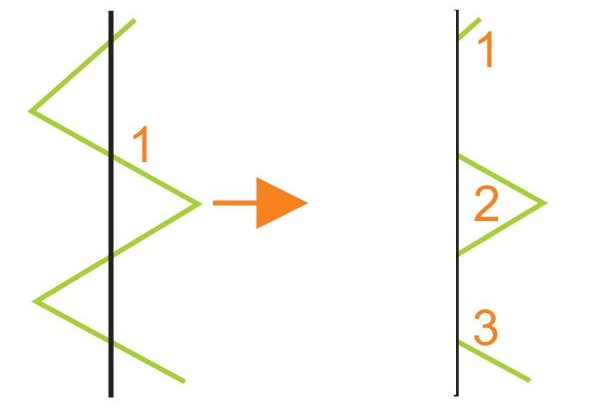 Figure 8 line processing
Figure 8 line processing
Typical area-elements in a map are used lakes, sea and wood …. With areas the same procedure as the one with lines can be applied. They will be divided at the border-lines into one ore more areas. There are a lot of mathematical solutions for this method as well, but sometimes the applications ar not free of bugs. Therefore no more considerations are necessary.
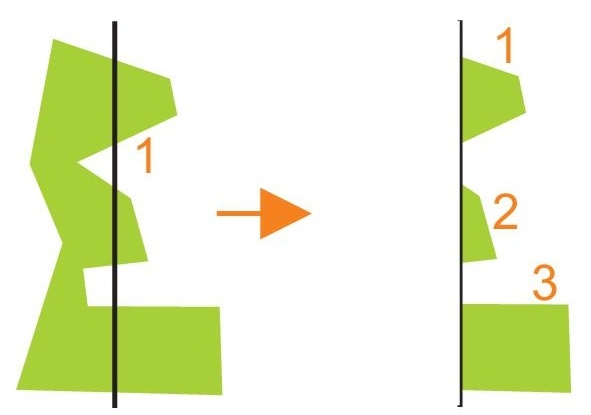 Figure 9 area processing
Figure 9 area processing
3.4 Point(Symbol) In a map there are a lot of point-elements. They can be the symbol for a city or for any point of interest. At first sight it seams clear, a point is inside or outside of the maprange. Although a point has only one coordinate in the gi-system, the outlook in the map is an area. The outlook comes out of libraries. The different gi-systems support raster and vector symbols. Because the symbol has an range, it is cut at the border-lines. This maybe is no problem for simple symbols. It is also possible, that a user cannot regocnize a clipped symbol.
For computeral solution of the border-cleaning the following parameters are necessary:
- list of layers (symbols), which will be deleted automatically
- list of layers, which will be moved automatically inside the maprange
- all layers, which are not in one of the two lists, will be cut
 Figure 9 symbol processing
Figure 9 symbol processing
There is the alternative solution to mention, if the rangearea of a symbol is to 75 % outside the border, then the symbol is deleted otherwise it is clipped or moved.
The text-information is one of the most important element for the good design of a map. Therefore special considerations are necessary. In a map there are different kinds of text in the eyes of the computer-application:
a) horizontal text
b) text with startpoint and direction
c) text between 2 points
d) text with a curved or linear base and individual spacing between the chars, e.g. name of a mountain

Figure 10 differend kinds of text-elements a), b) and c) can be combined to the kind ?text with start- and endpoint?.
Map-users cannot read cut text. It would be great, if the text were automatically modified at border-cleaning. To find the optimal position for an text, where it does not cover other texts or symbols. is a very complicated problem for computers. A lot of studies have been made and will be done on this, but in most cases they bring no perfect solutions for all kinds of data (Riedl-Kainz-Elmes, 2006). Therefore such automatic functions are missed in the popular cartographic- and gi-systems.
An approach for a good solution used is a kind of weight for the importance of a text. In the easiest case the weight 1=important, 0=unimportant.
- Due to the fact, that the moving of text is critical, text will not be moved, text will be scaled! As mentioned at the beginning of this paper, scaling of text is not gi-system compatible. So it is only possible to define, if text in text-layer ?a? is too large, move text to text-layer ?b?. The software-application gets a two column list. In the first column the text-layer, in which the text originally positioned, is listed, in the second column is the name of the text-layer, to which the text has been moved to. If the text uses individual char spacing, the application first tries to modify the spacing to a minimum. If this procedure does not succeed, the text is replaced.
- There is still text in the map, which is so much important that it cannot be scaled. This text will be placed automatically in a vertical position in the border. This kind of text is the only one, which disturbs the automatic process and has to be programmed clearly (solutions for two important texts, which are too close together …). The software-application gets a list of the layers for this work.
- All text-layers, which are not in the list, will be deleted
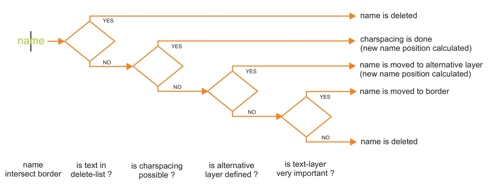
Figure 12 simplified text processing (special processing for multiline text is necessary)
When the output-map is a printed map, then a mix of the automatic process and the half-automatic process is maybe useful. The use of an automatic border-cleaning for maps on the Internet is a great quality improvement.
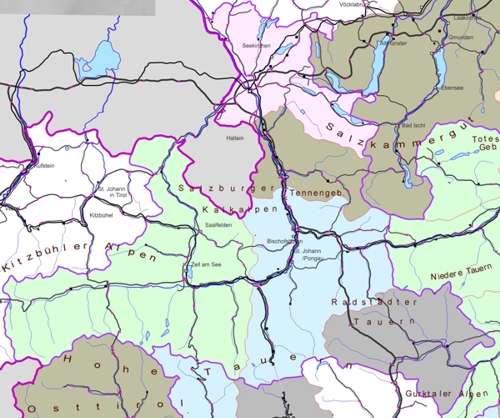
Figure 13 text processing map example
This paper shows, how with a useful IT-application a large portion of border-cleaning can be made easily and automatically. The described methods are tested in the cartographic-gi-application geoLion. This papers does not describe how elements on atlas pages will be generated automatically. From the author applications exist, which place pagenumbers automatically, grid for searching and geolocation, arrows to the next pages … This will be an extra theme for a paper.
Today it seems that border-cleaning is only a subject for the printed maps. But in future the maps on the Internet as well will have an automatic border-cleaning. Maybe the cartographers make pressure on this issue and give information to the Internet-mapping-producer? Most of the computers have today more power than the daily used applications need. The calculations can also run on the mapping-server in the cloud. So it will be no problem, to make border-cleaning ?on-the-fly?- receiving the data for a special range request - automatically! Border cleaning is a fascinating topic for all kinds of maps, whatever if a map tells a story or presents facts. It is part of a good design of a map and it is the criterium for the quality of a map!
Over the years I have had the great pleasure to work for different companies, which make different maps like surveyers, wastewater and gas companies, land-use planing specialists and mapping companies. Thank you for having a deeper look in your work and for the long discussions. Thank you for buying gi-solutions and for using my consulting services.